회고 프로젝트 - 1주차
서론
0주차에 진행한 설계를 바탕으로 1주차에는 기능 구현을 진행했다.
일정 상으로는 회원가입, 로그인, 로그아웃 그리고 회원탈퇴까지 구현하기로 했다. 하지만, 구현을 하다보니 시간이 남아 다음 주차에 예정되있던 문제 관련 기능을 1주차에 구현을 했다.
본론
스키마 생성
프로젝트에서 사용할 데이터베이스를 위해 먼저 스키마를 생성했다. (스키마 → 테이블 → 데이터) 교육 과정에서 제공된 SQL문을 가져다 썼기 때문에 스키마를 생성해 본 적이 없었다.
MySQL 상단 아이콘 중 원기둥 모양의 아이콘이 있다. 이를 클릭하면 다음과 같은 화면이 나온다.
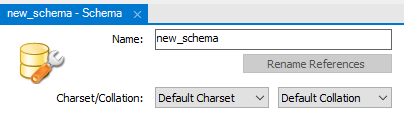
- Name : 생성할 스키마의 이름
- Charset
- 문자의 집합이며, 인코딩/디코딩 방식을 설정한다.
- 대표적으로 utf8, euckr 그리고 utf8mb4가 있다고 한다.
- utf8 : 영어와 특수문자 1byte, 한글 2~3byte로 표현
- euckr : 영어와 특수문자 1byte, 한글 2byte로 표현
- utf8mb4 : 영어와 특수문자 1byte, 한글 2~3byte, 이모지 4byte로 표현
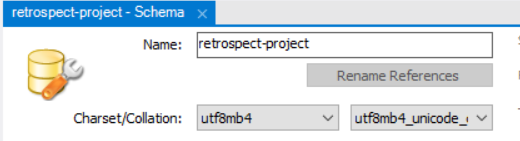
- 알고리즘 문제 설명에 이모지를 작성하는 경우가 있을 수 있기 때문에 utf8mb4로 설정했다.
- Collation
- Charset의 기반으로 인고딩/디코딩된 데이터의 정렬과 관련된 옵션이다.
- utf8 - utf-8 unicode-ci
- utf8mb4 - utf8mb4 unicode-ci
- Charset에 맞게 설정하지 않으면 정렬이 의도치 않게 작동된다고 한다.
- Charset의 기반으로 인고딩/디코딩된 데이터의 정렬과 관련된 옵션이다.
데이터 베이스 연동
스키마를 생성했다면, 이제 자바 애플리케이션과 데이터베이스를 연동할 차례이다. JPA 내부에 하이버네이트가 있기 때문에, JPA 의존성을 주입한다. 또한, 사용할 데이터베이스의 커넥트를 얻어야하기 때문에 관련 의존성도 추가한다.
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'com.mysql:mysql-connector-j'

의존성 주입이 끝나면, 애플리케이션 설정파일을 작성한다.
spring:
config:
import: application-mysql.yml
jpa:
database: mysql
hibernate:
ddl-auto: update
properties:
hibernate:
show_sql: true
format_sql: true
- config.import
- 데이터베이스에 접근하기 위해 데이터베이스 유저 이름과 비밀번호를 작성해야한다.
- 이를 작성하고 그대로 배포를 하게 되면, 개인정보 유출의 위험성이 존재한다.
/resources경로에application-{사용자정의}.yml의 이름으로 파일을 생성한다.- 내부에 사용할 데이터베이스 경로, 유저이름 그리고 비밀번호 등을 작성한다.
- 이후
.gitignore에 해당 파일을 추가한다. - show_sql, format_sql : 콘솔창에 출력되는 sql에 대한 설정이다.
- show_sql : sql 출력 여부
- format_sql : sql를 예쁘게 볼지 여부
유저 Entity
이제 엔티티를 이용한 테이블 생성을 진행한다. 유저는 이메일, 비밀번호, 레벨, 경험치 그리고 역할을 가지고 있어야 한다. 이것 저것 테스트를 하고 점검의 끝으로 다음과 같은 코드가 작성됐다.
@Entity
@Getter
@NoArgsConstructor(access = PROTECTED)
@Table(name = "user")
public class User {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@Column(nullable = false, unique = true, length = 100)
private String email;
@Column(nullable = false)
private String password;
@Column(insertable = false)
@ColumnDefault("1")
private int level;
@Column(insertable = false)
@ColumnDefault("0.0")
private double exp;
@Column(length = 5, insertable = false)
@ColumnDefault("'user'")
private String role;
@Builder
public User(String email, String password, int level, double exp, String role) {
this.email = email;
this.password = password;
this.level = level;
this.exp = exp;
this.role = role;
}
public void changePassword(String newPassword) {
this.password = newPassword;
}
}
- 빌더 패턴
- dto → entity로 전환되는 과정에서 코드를 깔끔하게 작성하고자 빌더 패턴을 추가했다.
- 또한, 필요한 데이터만 넘기기 위해서 중복된 생성자를 만드는 것이 아닌 빌더 패턴을 통해 코드의 간결화를 가져올 수 있기 때문에 추가했다.
- @NoArgsConstructor(access = PROTECTED)
- @NoArgsConstructor은 기본 생성자를 생성해주는 어노테이션이다.
- access 설정을 통해 기본 생성자의 접근 제어자를 설정할 수 있다.
- PROTECTED로 설정을 하면 기본 생성자의 접근 제어자를 protected로 선언한다.
- protected로 선언되면, 같은 패키지 혹은 상속받은 클래스만 접근할 수 있다.
- 접근 권한을 설정해주는 이유는 다음과 같다고 한다.
- 기본적으로 JPA에서는 기본 생성자를 요구한다.
- public로 기본 생성자를 설정할 경우, 무분별한 객체 생성을 막을 수 없다.
- 또한, 프록시를 조회하기 위해서는 private가 아닌 다른 접근 제어자로 설정을 해야한다.
- @Column의 insertable 옵션
- 기본값 설정을 위해 처음에는 @ColumnDefault() 어노테이션만 사용했다.
- @ColumnDefault() : 컬럼에 default 제약 조건을 추가
- @Column의 columnDefinition 옵션을 통해서도 가능
- 이메일과 비밀번호만 넘겨주면 나머지 값에는 기본값이 들어 갈 것이라고 기대를 했지만 다음과 같은 결과가 나왔다.
- 기본값 설정을 위해 처음에는 @ColumnDefault() 어노테이션만 사용했다.
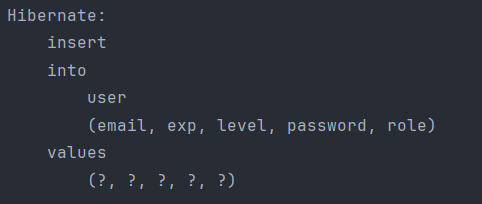
- 분명 email과 password만 넘겨줬는데, exp,level 그리고 role도 같이 sql문에 포함되서 넘어갔다.
- 데이터베이스를 확인해보니 다음과 같이 저장되어 있었다.

- role에는 null, exp와 level은 0이 들어가 있었다. 왜 일까 생각해보니 다음과 같은 결론이 나왔다.
- exp와 level의 경우 기본 타입이기 때문에 entity 생성 당시 기본 초기값으로 0.0과 0을 갖는다.
- role의 경우 String 원시 타입으로 선언되어 있기 때문에 entity 생성 당시 기본 초기값으로 null을 갖는다.
- exp, level 그리고 role은 데이터베이스에 초기값 설정을 위임하기 위해서 null을 허용했으며, 초기 값이 그대로 들어갔다.
- 이를 해결하기 위해 방법을 찾아봤고 두 가지 방법이 있었다.
- @DynamicInsert
- Insert 시점에 null이 아닌 컬럼만 포함시킨다.
- 하지만 이렇게 되면 role만 해결이 되고 exp, level은 해결되지 않는다.
- @Column의 insertable 옵션
- true로 설정하면 Insert 시점에 컬럼을 포함시키지 않는다.
- 세 컬럼에 모두 적용을 했고, 다음과 같은 쿼리가 날라갔다.
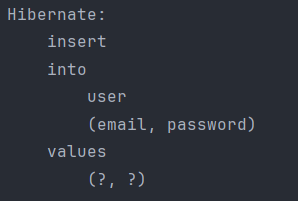
- 데이터베이스를 확인하니 다음과 같이 정상적으로 기본값이 저장됐음을 확인할 수 있었다.

- 이것도 안되면 @Query를 사용해서 직접 쿼리를 작성해야하나 생각이 들었다.
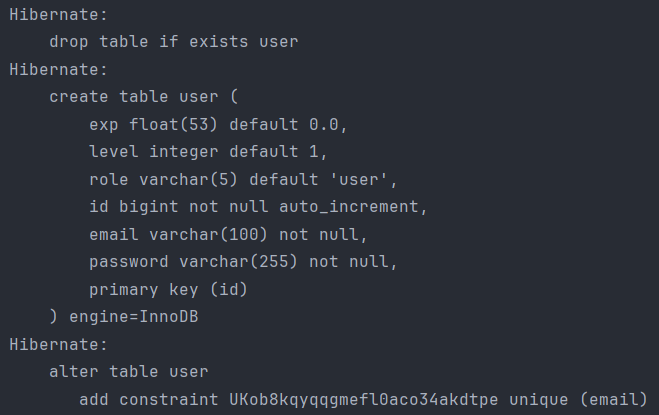
최종으로 user 테이블 생성 쿼리는 다음과 같다.
인터셉트 빈 등록
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginCheckInterceptor())
.order(1)
.addPathPatterns("/**")
.excludePathPatterns("/login", "/register", "/");
}
}
실습 과제에서 인터셉트를 등록하는 코드를 이렇게 작성했다. 문뜩 생각이 든 것이, new 연산자로 등록을 하면 클라이언트의 요청때마다 새로운 인터셉트가 생성되는 것이 아닐까라는 의심이 들었다. 그럼 이를 싱글톤으로 등록하기 위해서는 컴포넌트 스캔단계에서 인터셉트를 탐색해서 빈으로 등록하면 되기 때문에, 인터셉트에 컴포넌트 어노테이션을 달아줬다.
@Component
public class CertInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
return request.getSession().getAttribute("userId") != null;
}
}
구현이 끝나고, 진짜로 요청때마다 생성하는지 테스트를 해봤다. 요청때마다 인터셉터 객체의 해시 코드를 출력하도록 했다.
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println(System.identityHashCode(this));
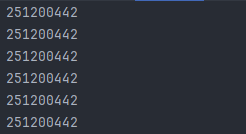
예상했던 것과는 다른 결과가 나왔다. 요청때마다 동일한 해시 코드를 출력하고 있다. 테스트 방법이 잘못됐는지, 아니면 인터셉트를 스프링에서 싱글톤으로 등록해주는지, MVC Request Life Cycle를 다시 한 번 확인해봐야겠다.
쿼리 메소드 get vs find
아이디를 통해 유저를 조회하기 위해서 쿼리 메소드를 통해 메소드를 선언해야했다. 여기서 get을 써야하는지 find를 써야하는지 혼돈이 됐다. 구현 당시에는 get을 사용했다. 뭔가 얻는다는 느낌이 강했다고 생각했던 것 같다.
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
User getByUsername(String username);
}
찾아보니, jpa에서 getById의 경우 데이터가 없으면 널포인트를 발생시키고, findById의 경우 Optional에 감싸서 데이터를 가져온다. get은 맨 손으로 얻으러 갔다가 없으면 null이라도 찾아서 오는 느낌, find는 박스를 들고 찾으러 갔다가 없으면 그냥 빈 박스를 가져다주는 느낌..?또한, get은 프록시를 참조하기 때문에 정보를 요청하는 시점에 DB를 조회한다.
Optional의 경우에도 박싱 언박싱 과정에서 성능 저하가 생긴다고 하는데, 현재 프로젝트에서 큰 성능 저하를 가져오지는 않다고 판단했다. 그렇기 때문에 null값을 안전하게 다루기 위해 find를 사용하는 것이 좋아보인다. 지연 로딩이 필요한 경우에는 get를 사용할 수 있지만, 프로젝트에서 연관관계가 있는 객체의 지연 로딩 외에는 지연 로딩이 필요한 경우가 있을지 의문이다.
상황에 맞게 사용하자. (find로 바꾸러 가자)
JSON 다루기
데이터베이스 컬럼으로 JSON을 저장하도록 설계를 했고, 엔티티에서 해당 컬럼이 JSON으로 저장됨을 명시해야한다. 또한, JSON으로 저장된 데이터를 읽어오는 과정도 진행해야한다. 이를 위해 hypersistence-tuils 이라는 라이브러리를 사용했다.
implementation 'io.hypersistence:hypersistence-utils-hibernate-63:3.8.1'
해당 라이브러리는 하이버네이트의 부가 기능이기 때문에 하이버네이트를 사용하지 않는다면 적용할 수 없다고 한다. 해당 라이브러리를 통해 JPA에서 JSON 형태의 자료를 데이터베이스 컬럼에 삽입할 수 있다.
@Type(JsonType.class)
@Column(nullable = false, columnDefinition = "json")
private Map < String, String > runtime;
@Type 어노테이션은 하이버네이트에서 제공하는 어노테이션으로, 데이터베이스에 저장될 데이터의 타입을 지정할 수 있다. 해당 값으로 hypersistence-tuils 에서 제공하는 JsonType 클래스를 설정한다. Json를 하나의 컬럼에 여러 개 저장하기 위해서는 List<Map<String, String>> 의 자료형으로 설정한다.

설정한 자료형에 맞게 POST 요청을 하면 정상적으로 데이터베이스 컬럼에 JSON이 저장됨을 확인할 수 있다. 데이터베이스에서 가져올때는 Map 자료형으로 가져오면 된다.
동적 쿼리
여기서 애를 많이 쓴 것 같다. 문제 검색은 id, 제목, 난이도 그리고 알고리즘 분류를 설정해서 검색한다. 하나의 설정이라도 들어오면, 그 설정을 바탕으로 조회를 해야한다. 이름바 동적 쿼리. 학습 단계에서 JPA는 동적 쿼리 구현이 어려워 QueryDSL 등 다른 라이브러리리를 사용해야하는 수요가 있다고 인지하고 넘어갔다.
실제로 만나니 답이 없었다. Q 객체 ? 의존성만 넣으면 끝날 줄 알았지만 기타 설정 등등 해당 라이브러리로 구현을 하면 가독성이 좋은 동적 쿼리 코드가 나오는데, 러닝 커브가 좀 있는 것 같았다. 실제로 하다가 이건 스읍.. 하고 롤백했다.
일단 임시로 이전에 사용했던 JPQL를 사용했다. 개인적으로 JPQL이 편하다고 생각한다. 코드가 좀 지저분해질수 있지만, 쿼리문이 직접 보이고 쿼리에 조금 익숙하다고 생각해서 편한 것 같다. 학교에서 빌린 김영한님의 JPA 도서를 참고했다.
컨트롤러
@GetMapping("/problem")
public ResponseEntity < List < ResponseProblem >> findProblemByParams(
@RequestParam(value = "id", required = false) Long id,
@RequestParam(value = "title", required = false) String title,
@RequestParam(value = "level", required = false) Integer level,
@RequestParam(value = "algorithms", required = false) String algorithms
) {
List < ResponseProblem > problemByParams = problemService.findProblemByParams(id, title, level, algorithms);
return ResponseEntity.ok(problemByParams);
}
쿼리 파라미터를 이용해서 요청을 받을려 했는데, 명시된 파라미터 중 하나의 값이라도 안 들어오면 오류를 뱉었다. 하나만 들어와도 진행해야하기 때문에 찾아보니, required 옵션을 통해 선택적으로 받을 수 있었다.
또한, 프로젝트를 진행하면서 원시형이 좀 좋다(?)라는 느낌을 받은 것 같다. 기본 자료형으로 선언을 하면 자료형 초기값이 들어가기 때문에, 입력을 안해도 초기값이 들어가버린다. 가령 난이도가 0인 문제가 있는데, 클라이언트는 난이도로 검색을 안했는데도 난이도가 0인 문제가 나와버린다.
원시형으로 선언을 하면 null로 초기화가 되기 때문에 null 체크만 잘 하면 값이 들어왔는지 안 들어왔는지 확인할 수 있다.
서비스
public List < ResponseProblem > findProblemByParams(
Long id, String title, Integer level, String algorithms
) {
StringBuilder jpql = getBuilder(id, title, level, algorithms);
TypedQuery < Problem > query = entityManager.createQuery(jpql.toString(), Problem.class);
if (id != null) query.setParameter("id", id);
if (title != null) query.setParameter("title", "%" + title + "%");
if (level != null) query.setParameter("level", level);
if (algorithms != null) query.setParameter("algorithms", "%" + algorithms + "%");
List < Problem > resultList = query.getResultList();
return resultList.stream().map(ResponseProblem::from).toList();
}
private static StringBuilder getBuilder(Long id, String title, Integer level, String algorithms) {
StringBuilder jpql = new StringBuilder("select p from Problem p");
List < String > criteria = new ArrayList < > ();
if (id != null) criteria.add(" p.id = :id");
if (title != null) criteria.add(" p.title like :title");
if (level != null) criteria.add(" p.level = :level");
if (algorithms != null) criteria.add(" p.algorithms like :algorithms");
if (!criteria.isEmpty()) jpql.append(" where ");
for (int i = 0; i < criteria.size(); i++) {
if (i > 0) jpql.append(" and ");
jpql.append(criteria.get(i));
}
return jpql;
}
getBuilder 메소드에서는 JPQL에 사용될 쿼리를 생성한다. null 체크를 통해 값이 들어온 것에 대해 문자열을 추가추가하고 이를 반환한다.
findProblemByParams 에서는 받은 문자열에 setParameter 메소드를 이용해서 파라미터 바인딩을 진행한다. 이후, 결과를 받아 스트림을 통해 DTO로 변환을 하고 반환한다.
마무리
이번 주차는 몰입을 제대로 한 느낌이 들었다. 개발 과정에서 문제가 발생하면 이를 끝까지 해결할려고 노력했고, 해결됐을 때의 그 느낌은 새로운 도파민이였다.
예정했던 일정보다 더 많은 것을 수행했다. 많이 했다고 좋아할 것이 아닌, 과정속에서 배운 것이 있는지, 실속없이 무작정 코딩만 한 것이 아닌지 등 짚고 넘어가야할 것이 있다고 생각이 든다. 한 7:3 정도 비율로 진행한 것 같다. 무작정 구글링을 하지 않고, 스스로 해결해볼려고 노력했다.
또한, 구현 과정에서 설계 내용을 좀 많이 고쳤다. 설계가 완벽하다고 생각이 들었지만, 막상 구현을 해보면 설계가 부족하다고 느끼거나 잘못된 부분이 있는 등 완벽하지 못했다. 설계에서 조금씩 문제가 터지니 구현에서도 갈피를 못 잡는 등 설계의 중요성을 깨달은 주차였다.